STT(Speech-to-Text)란?
사람이 말하는 음성 언어를 컴퓨터가 해석해 그 내용을 문자 데이터로 전환하는 처리

STT(Speech-to-Text), Voice Recognition 또는 인공 청각이라고도 표현합니다.
뜻 그대로 사람의 음성 인터페이스를 통해 텍스트(문자) 데이터를 추출해내는 것이죠.
STT 기술에서는 이러한 비언어적 요소 없이 음성만으로 어떻게 정확한 내용을 처리 해낼 수 있을까요?
STT 핵심 요소 기술
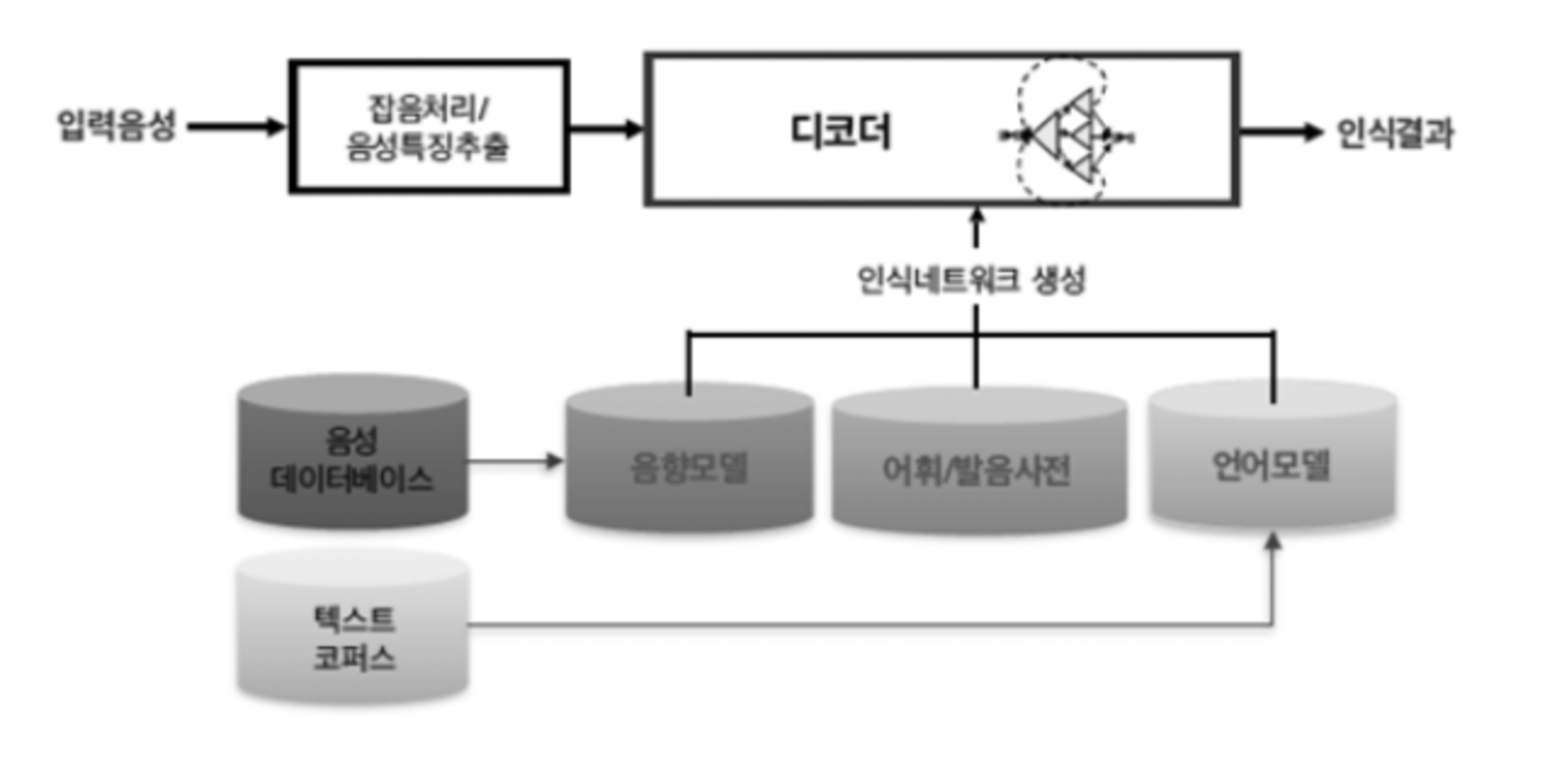
STT를 위한 데이터에는 크게 음향학적 관점과 언어학점 관점으로 볼 수 있습니다.
음향학점 관점은 말하는 이, 공간, 노이즈 등의 환경적인 데이터가 주를 이루고 언어학적 관점에서는 어휘, 문맥, 문법 등을 모델링하기 위한 언어 데이터가 주를 이룹니다.
오프라인 학습 단계
STT는 크게 음성/언어 데이터로부터 인식 네트워크 모델을 생성
온라인 탐색 단계
사용자가 발성한 음성을 인식
디코더(Decoder)
STT 엔진은 음성과 언어 데이터의 사전 지식을 사용해서 음성 신호로부터 문자 정보를 출력하는데 이 때 해석하는 STT 알고리즘.
디코딩 단계에서는 학습 단계 결과인 음향 모델(Acoustic Model), 언어 모델(Language Model)과 발음 사전(Pronunciation Lexicon)을 이용하여 입력된 특징 벡터를 모델과 비교, 스코어링(Scoring)하여 단어 열을 최종 결정 짓습니다.
음향 모델링
해당 언어의 음운 환경별 발음의 음향적 특성을 확률 모델로 대표 패턴을 생성하는 과정.
언어 모델링
어휘 선택, 문장 단위 구문 구조 등 해당 언어의 사용성 문제에 대해 문법 체계를 통계적으로 학습하는 과정
또한 발음 사전 구출을 위해서는 텍스트를 소리나는 대로 변환하는 음소변환(Grapheme-to-Phoneme) 구현 과정이 필요
STT 성능
STT의 성능은 DB 크기와 품질에 비례하여 향상될 수 있습니다.
상용 서비스에 적용되는 음향 모델의 대부분 확률 통계 방식인 HMM(Hidden Markov Model) 기반으로 이루어졌으며, 2010년대에 들어서면서 딥러닝 기반으로 HMM/DNN 방식으로 단어 인식 오류를 개선하여 20%의 성능 향상을 이루었다.
최근에는 시퀀스-투-시퀀스(Sequence-to-Sequence) 방식의 RNN(Recurrent Neutral Network) 기반으로 속도와 성능 면에서 좋은 결과를 가져왔습니다.
음성인식에서도 번역어(End-to-End) 학습 방식의 발전으로 일련의 오디오 특징을 입력으로 일련의 글자(character) 또는 단어들을 출력으로 하는 단일 함수를 학습할 수 있게 되었습니다.
또한 CTC**(Connectionist Temporal Classification)** 이라는 모델로 입력 데이터와 레이블 사이의 음성 정렬(alignment) 정보가 없어도 학습이 가능하게 되었습니다.
참조 :
'안드로이드' 카테고리의 다른 글
| STT (구글) - 샘플코드 (0) | 2022.11.09 |
|---|---|
| STT(구글) - SpeechRecognizer Document (0) | 2022.11.09 |
| RxJava2을 사용한 Retrofit통신 (0) | 2022.11.04 |
| [Android] DB Realm Migration (0) | 2022.11.04 |
| [Android] Lottie 애니메이션 (0) | 2022.11.04 |